Make - LLMs Actor integration
Apify Scraper for LLMs
Apify Scraper for LLMs from Apify is a web browsing module for OpenAI Assistants, RAG pipelines, and AI agents. It can query Google Search, scrape the top results, and return page content as Markdown for downstream AI processing.
To use these modules, you need an Apify account and an API token. You can find your token in the Apify Console under Settings > Integrations. After connecting, you can automate content extraction and integrate results into your AI workflows.
Connect Apify Scraper for LLMs
-
Create an account at Apify. You can sign up using your email, Gmail, or GitHub account.
-
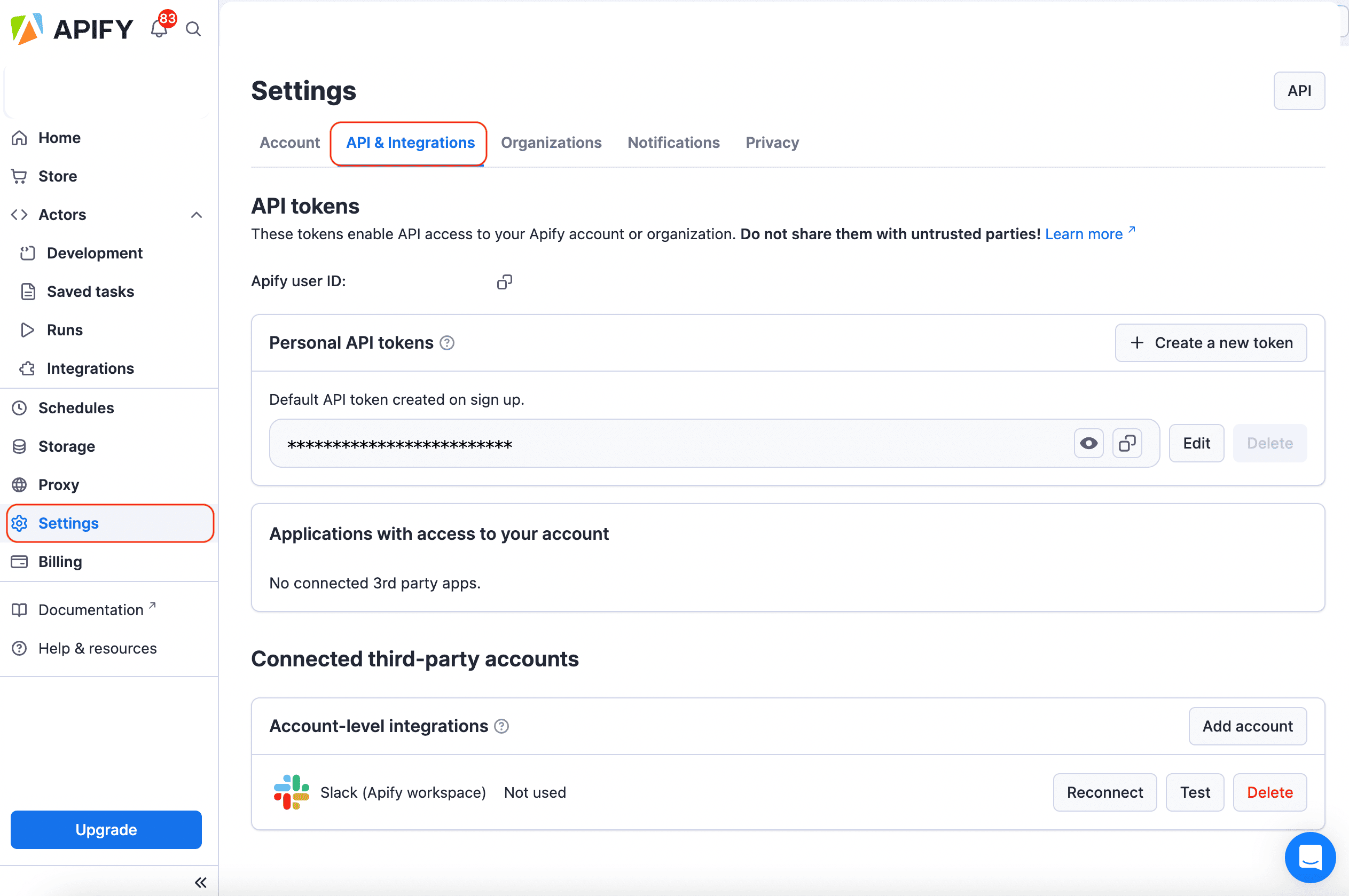
To connect your Apify account to Make, you can use an OAuth connection (recommended) or an Apify API token. To get the token, go to Settings > API & Integrations in the Apify Console.
-
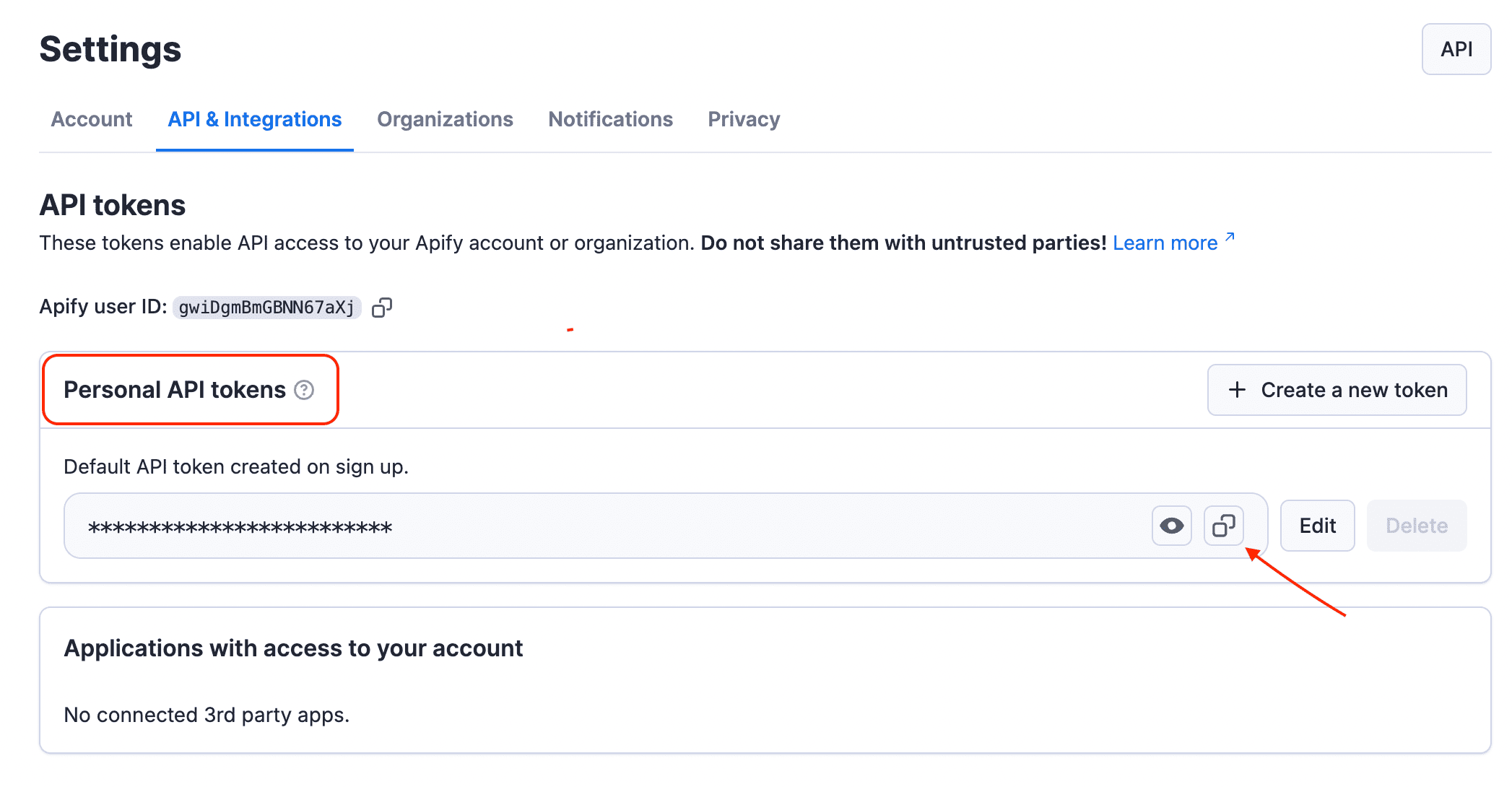
Find your token under Personal API tokens. You can also create a new token with custom permissions by clicking + Create a new token.
-
Click the Copy icon to copy your API token, then return to your Make scenario.
-
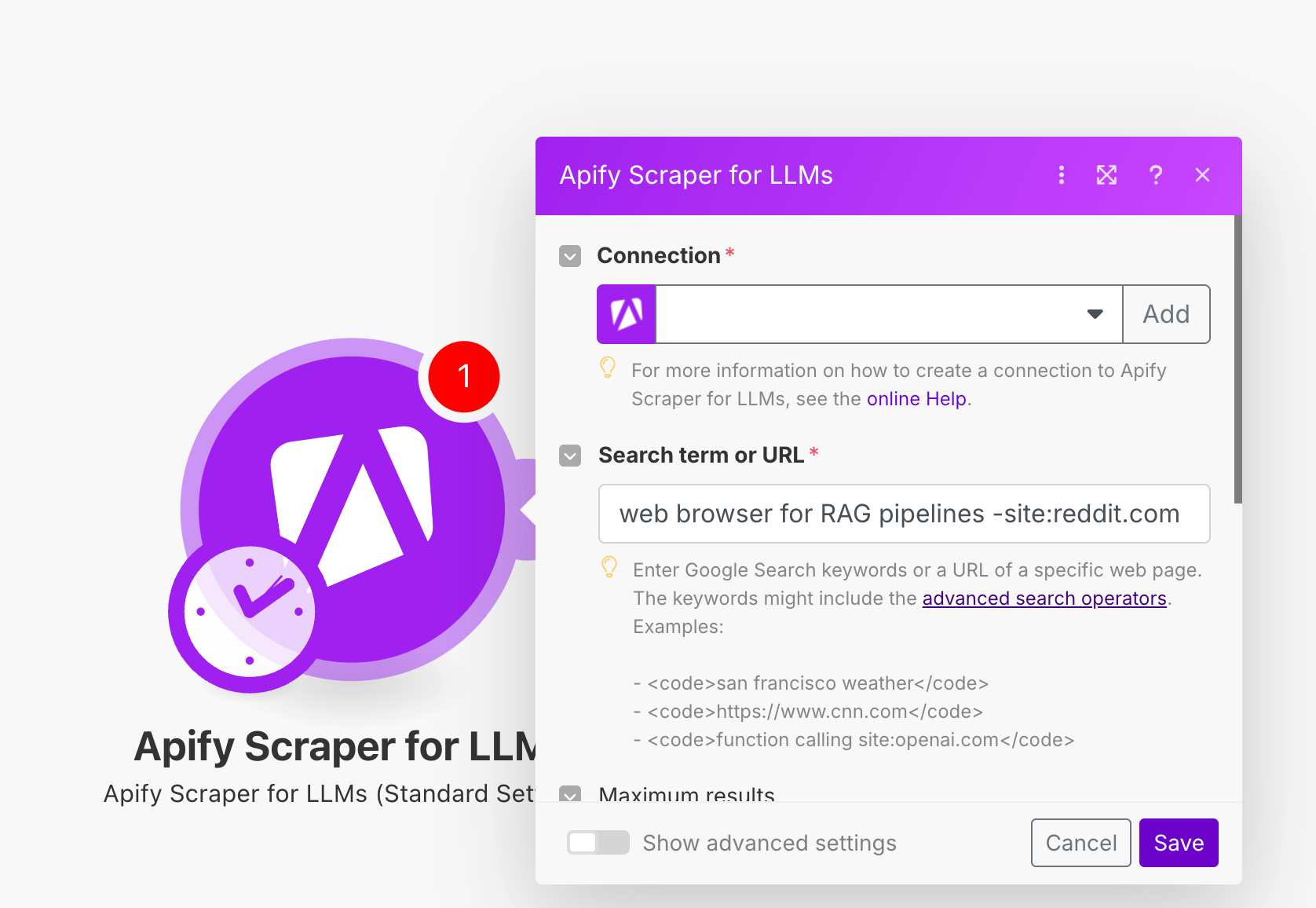
In Make, click Add to open the Create a connection dialog of the chosen Apify Scraper module.
-
In the API token field, paste your token, provide a clear Connection name, and click Save.
Once connected, you can build workflows that search the web, extract content, and pass it to your AI applications.
Apify Scraper for LLMs modules
After connecting the app, you can use two modules to search and extract content.
Standard Settings module
Use Standard Settings to quickly search the web and extract content with optimized defaults. This is ideal for AI agents that need to answer questions or gather information from multiple sources.
The module supports two modes:
-
Search mode (keywords)
- Queries Google Search with your keywords (supports advanced operators)
- Retrieves the top N organic results
- Loads each result and extracts the main content
- Returns Markdown-formatted content
-
Direct URL mode (URL)
- Navigates to a specific URL
- Extracts page content
- Skips Google Search
How it works
When you provide keywords, the module runs Google Search, parses the results, and collects organic URLs. For content extraction, it loads pages, waits for dynamic content to render, removes clutter, extracts the main content, and converts it to Markdown. Finally, it generates output by combining content, adding metadata and sources, and formatting everything for AI consumption.
Output data
{
"query": "web browser for RAG pipelines -site:reddit.com",
"crawl": {
"httpStatusCode": 200,
"httpStatusMessage": "OK",
"loadedAt": "2025-06-30T10:15:23.456Z",
"uniqueKey": "https://example.com/article",
"requestStatus": "handled"
},
"searchResult": {
"title": "Building RAG Pipelines with Web Browsers",
"description": "Integrate web browsing into your RAG pipeline for real-time retrieval.",
"url": "https://example.com/article",
"resultType": "organic",
"rank": 1
},
"metadata": {
"title": "Building RAG Pipelines with Web Browsers",
"description": "Add web browsing to RAG systems",
"languageCode": "en",
"url": "https://example.com/article"
},
"markdown": "# Building RAG Pipelines with Web Browsers\n\n..."
}
Configuration (Standard Settings)
- Search query: Google Search keywords or a direct URL
- Maximum results: Number of top search results to process (default: 3)
- Output formats: Markdown, text, or HTML
- Remove cookie warnings: Dismiss cookie consent dialogs
- Debug mode: Enable extraction diagnostics
Advanced Settings module
Advanced Settings give you full control over search and extraction. Use it for complex sites or production RAG pipelines.
Key features
- Advanced search options: full Google operator support
- Flexible crawling tools: browser-based (Playwright) or HTTP-based (Cheerio)
- Proxy configuration: handle geo-restrictions and rate limits
- Granular content control: include, remove, and click selectors
- Dynamic content handling: wait strategies for JavaScript rendering
- Multiple output formats: Markdown, HTML, or text
- Request management: timeouts, retries, and concurrency
Configuration options
- Search: query, max results (1–100), SERP proxy group, SERP retries
- Scraping: tool (browser-playwright, raw-http), HTML transformer, selectors (remove/keep/click), expand clickable elements
- Requests: timeouts, retries, dynamic content wait
- Proxy: use Apify Proxy, proxy groups, countries
- Output: formats, save HTML/Markdown, debug mode, save screenshots
Output data
{
"query": "advanced RAG implementation strategies",
"crawl": {
"httpStatusCode": 200,
"httpStatusMessage": "OK",
"loadedUrl": "https://ai-research.com/rag-strategies",
"loadedTime": "2025-06-30T10:45:12.789Z",
"referrerUrl": "https://www.google.com/search?q=advanced+RAG+implementation+strategies",
"uniqueKey": "https://ai-research.com/rag-strategies",
"requestStatus": "handled",
"depth": 0
},
"searchResult": {
"title": "Advanced RAG Implementation: A Complete Guide",
"description": "Cutting-edge strategies for RAG systems.",
"url": "https://ai-research.com/rag-strategies",
"resultType": "organic",
"rank": 1
},
"metadata": {
"canonicalUrl": "https://ai-research.com/rag-strategies",
"title": "Advanced RAG Implementation: A Complete Guide | AI Research",
"description": "Vector DBs, chunking, and optimization techniques.",
"languageCode": "en"
},
"markdown": "# Advanced RAG Implementation: A Complete Guide\n\n...",
"debug": {
"extractorUsed": "readableText",
"elementsRemoved": 47,
"elementsClicked": 3
}
}
Use cases
- Quick information retrieval for AI assistants
- General web search integration and Q&A
- Production RAG pipelines that need reliability
- Extracting content from JavaScript-heavy sites
- Building specialized knowledge bases and research workflows
Best practices
To get the best search results, use specific keywords and operators, and exclude unwanted domains with -site:. For better performance, use HTTP mode for static sites and only switch to browser mode when necessary. You can also tune concurrency settings based on your needs. To maintain content quality, remove non-content elements, choose the right HTML transformer, and enable debug mode when troubleshooting. Finally, ensure reliable operation by setting appropriate timeouts and retries, and monitoring HTTP status codes for errors.
Other scrapers available
There are other native Make Apps powered by Apify. You can check out Apify Scraper for:
And more! Because you can access any of thousands of our scrapers on Apify Store by using the general Apify connections.